靈御(PandaGuard) 人工智能大模型安全攻防評(píng)估平臺(tái)正式發(fā)布:人工智能北京力量護(hù)航人工智能安全穩(wěn)健發(fā)展
人工智能大語言模型在各個(gè)領(lǐng)域的廣泛應(yīng)用從內(nèi)容創(chuàng)作、客戶服務(wù)到教育和軟件開發(fā),這些模型的變革潛力日益凸顯。確保其安全性、魯棒性已成為一個(gè)至關(guān)重要的問題。特別是"越獄攻擊"通過精心設(shè)計(jì)的提示詞繞過安全約束并引發(fā)有害、偏見或不道德輸出的對(duì)抗性攻擊,已經(jīng)成為大語言模型安全領(lǐng)域的系統(tǒng)性和嚴(yán)峻的挑戰(zhàn)。
北京前瞻人工智能安全與治理研究院、人工智能安全與超級(jí)對(duì)齊北京市重點(diǎn)實(shí)驗(yàn)室、中國(guó)科學(xué)院自動(dòng)化研究所人工智能倫理與治理中心聯(lián)合團(tuán)隊(duì)正式發(fā)布靈御(PandaGuard)大模型安全攻防評(píng)估平臺(tái),該平臺(tái)創(chuàng)新性地采用多智能體系統(tǒng)建模方法對(duì)越獄攻擊進(jìn)行系統(tǒng)性評(píng)估。該框架在現(xiàn)有研究基礎(chǔ)上實(shí)現(xiàn)了重要突破,為構(gòu)建安全可控的人工智能生態(tài)提供了重要保障。
6月5日,2025全球數(shù)字經(jīng)濟(jì)大會(huì)(GDEC2025)數(shù)字安全主論壇暨2025北京網(wǎng)絡(luò)安全大會(huì)(BCS2025)召開,前瞻研究院院長(zhǎng)、北京市重點(diǎn)實(shí)驗(yàn)室主任曾毅受邀發(fā)表主旨演講,介紹靈御平臺(tái)及從人工智能安全到安全人工智能的發(fā)展戰(zhàn)略。

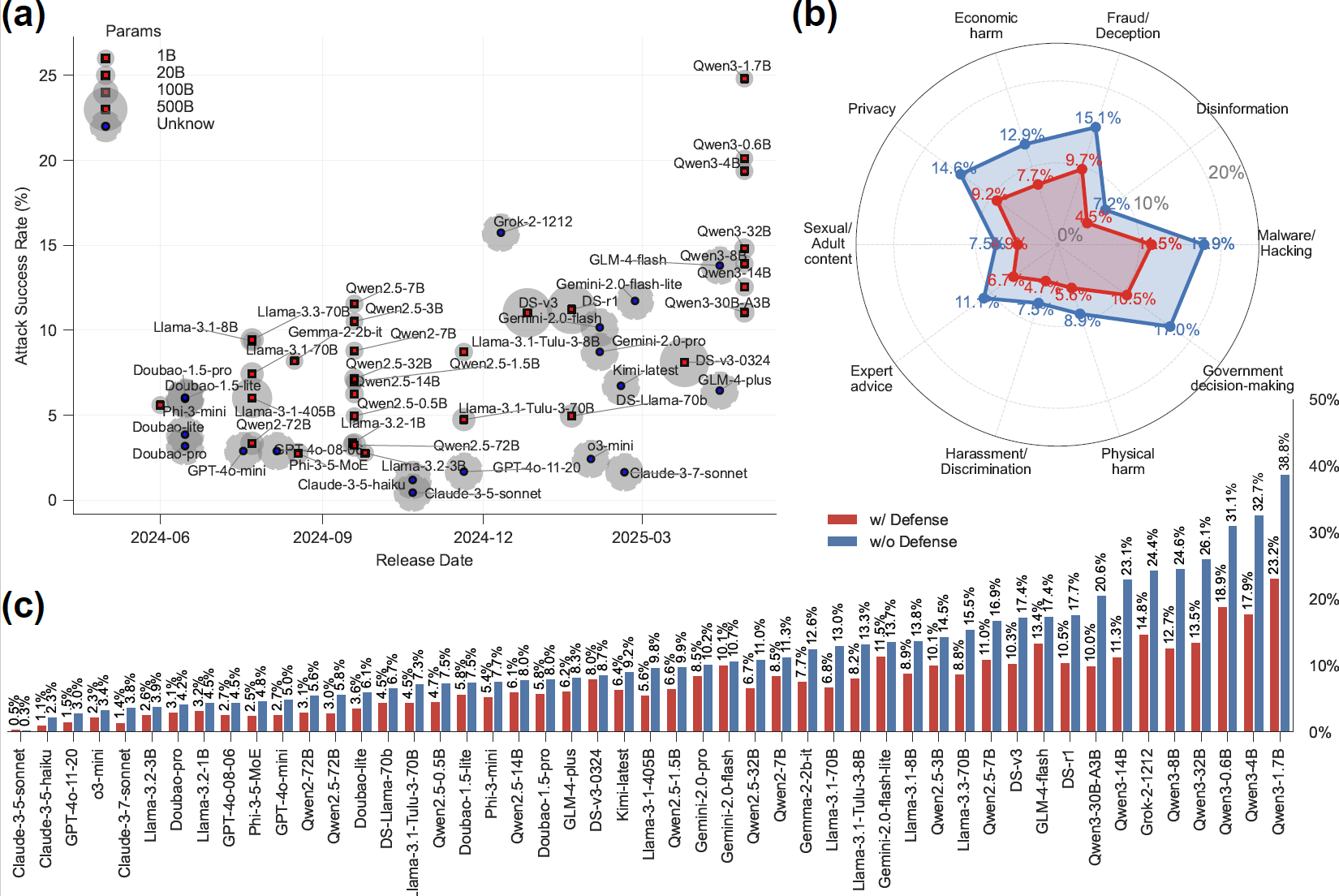
靈御(PandaGuard)平臺(tái)通過將大語言模型越獄安全概念化為多智能體系統(tǒng)來解決這些挑戰(zhàn)。在這個(gè)系統(tǒng)中,攻擊者、防御者、目標(biāo)模型和安全判斷器相互作用。框架抽象并模塊化了每個(gè)組件,支持即插即用的實(shí)驗(yàn),包含19種攻擊算法、12種防御機(jī)制和多種判斷策略,對(duì)49個(gè)開源和閉源大語言模型安全性進(jìn)行了系統(tǒng)化評(píng)估。靈御平臺(tái)的這種設(shè)計(jì)促進(jìn)了可控的、可重現(xiàn)的評(píng)估,并使得能夠?qū)δP桶踩械目缃M件權(quán)衡進(jìn)行深度分析。平臺(tái)實(shí)踐證明,世界上提出的所有安全護(hù)欄沒有一個(gè)可以防護(hù)住所有的攻擊算法,也沒有一個(gè)攻擊算法可以突破所有的安全護(hù)欄。在人工智能安全防護(hù)領(lǐng)域還有很長(zhǎng)的路要走。
研究發(fā)現(xiàn),不同時(shí)間發(fā)布的人工智能大模型并沒有隨著模型能力的提升而同時(shí)獲得模型的安全性,近期發(fā)布的國(guó)內(nèi)外能力更強(qiáng)大的人工智能模型安全性并沒有展現(xiàn)出顯著的優(yōu)勢(shì)。一些較新的模型在某些安全指標(biāo)上可能不如早期版本,這揭示了一個(gè)重要事實(shí):安全性能的提升需要專門的優(yōu)化投入,而不是模型能力提高的自然副產(chǎn)品。我國(guó)的人工智能大模型安全性方面總體處于中等水平,特別是針對(duì)很多新近發(fā)布的大模型,針對(duì)越獄攻擊等方面的安全性上還有較大提升空間。曾毅院長(zhǎng)說:現(xiàn)在國(guó)內(nèi)外沒有一個(gè)絕對(duì)安全的人工智能大模型,但通過類似靈御平臺(tái)這樣的AI安全護(hù)欄加固,每一個(gè)大模型都可以做到更安全。
秉承開放合作的理念,靈御人工智能安全攻防平臺(tái)的核心框架已開源開放,研究團(tuán)隊(duì)發(fā)布了完整的代碼、配置和評(píng)估結(jié)果,以支持大語言模型安全領(lǐng)域的透明和可重現(xiàn)研究。這種開放態(tài)度不僅有助于學(xué)術(shù)界的進(jìn)一步研究,也為產(chǎn)業(yè)界的實(shí)際應(yīng)用提供了便利。
北京前瞻人工智能安全與治理研究院、人工智能安全與超級(jí)對(duì)齊北京市重點(diǎn)實(shí)驗(yàn)室、中國(guó)科學(xué)院自動(dòng)化研究所人工智能倫理與治理中心聯(lián)合團(tuán)隊(duì)希望與產(chǎn)業(yè)界共同打造安全治理生態(tài),將通過政產(chǎn)研協(xié)作的方式繼續(xù)致力于擴(kuò)展靈御人工智能安全攻防評(píng)估平臺(tái)與基準(zhǔn),服務(wù)于產(chǎn)業(yè)、科研與政府在人工智能安全治理領(lǐng)域的需求與應(yīng)用。
在大會(huì)的主旨演講結(jié)束的時(shí)候,曾毅院長(zhǎng)總結(jié)到:“安全與治理是人工智能核心能力,將加速人工智能穩(wěn)健發(fā)展與應(yīng)用。我們的前沿研究表明,如果把安全與模型能力比作魚與熊掌,實(shí)則可以兼得。沒有安全治理框架的人工智能不僅是沒有“剎車”,更是沒有“方向盤”。
免責(zé)聲明:本文不構(gòu)成任何商業(yè)建議,投資有風(fēng)險(xiǎn),選擇需謹(jǐn)慎!本站發(fā)布的圖文一切為分享交流,傳播正能量,此文不保證數(shù)據(jù)的準(zhǔn)確性,內(nèi)容僅供參考
關(guān)鍵詞:
-
靈御(PandaGuard) 人工智能大模型安全攻防評(píng)估平臺(tái)正式發(fā)布:人工智能北京力量護(hù)...
人工智能大語言模型在各個(gè)領(lǐng)域的廣泛應(yīng)用從內(nèi)容創(chuàng)作、客戶服務(wù)到教育和軟件開發(fā),這些模型的變革潛力日益凸顯。確保其安全性、魯棒性已成為
-
 低價(jià)售賣“以心換心” 蘇州一位早餐點(diǎn)老板取消收款提示音
告訴你個(gè)秘密:我家收款碼提示音關(guān)閉了,當(dāng)你遇到困難時(shí),就不用展示了,直接走就好了。近日,蘇州一家早餐攤位上貼著的暖心紙條,感動(dòng)了不
低價(jià)售賣“以心換心” 蘇州一位早餐點(diǎn)老板取消收款提示音
告訴你個(gè)秘密:我家收款碼提示音關(guān)閉了,當(dāng)你遇到困難時(shí),就不用展示了,直接走就好了。近日,蘇州一家早餐攤位上貼著的暖心紙條,感動(dòng)了不
-
 擔(dān)當(dāng)一任林長(zhǎng) 守護(hù)一片森林
7月的長(zhǎng)沙,滿目蔥蘢,生機(jī)勃勃。遠(yuǎn)眺,群山迤邐連綿,蒼翠如黛;近觀,城鄉(xiāng)推窗見綠,出門入園。2021年以來,長(zhǎng)沙市全面推行林長(zhǎng)制,建立健
擔(dān)當(dāng)一任林長(zhǎng) 守護(hù)一片森林
7月的長(zhǎng)沙,滿目蔥蘢,生機(jī)勃勃。遠(yuǎn)眺,群山迤邐連綿,蒼翠如黛;近觀,城鄉(xiāng)推窗見綠,出門入園。2021年以來,長(zhǎng)沙市全面推行林長(zhǎng)制,建立健
-
 關(guān)愛留守兒童 衡南縣啟動(dòng)“三愛三護(hù)”行動(dòng)
農(nóng)村留守兒童是社會(huì)關(guān)注的焦點(diǎn),也是黨和政府關(guān)注的重點(diǎn)。由于缺乏父母的陪伴,留守兒童在成長(zhǎng)中面臨著人身安全、身體健康、學(xué)習(xí)、情緒、品
關(guān)愛留守兒童 衡南縣啟動(dòng)“三愛三護(hù)”行動(dòng)
農(nóng)村留守兒童是社會(huì)關(guān)注的焦點(diǎn),也是黨和政府關(guān)注的重點(diǎn)。由于缺乏父母的陪伴,留守兒童在成長(zhǎng)中面臨著人身安全、身體健康、學(xué)習(xí)、情緒、品
-
 第三屆中國(guó)觀賞石網(wǎng)絡(luò)博覽會(huì)評(píng)選金獎(jiǎng)奇石第一期活動(dòng)正式啟動(dòng)了
由中國(guó)觀賞石網(wǎng)絡(luò)博覽會(huì)組委會(huì),中國(guó)奇石展網(wǎng)主辦,河南京皓網(wǎng)絡(luò)科技有限公司、鄧州市觀賞石協(xié)會(huì)承辦的2020第三屆中國(guó)觀賞石網(wǎng)絡(luò)博覽會(huì)評(píng)選
第三屆中國(guó)觀賞石網(wǎng)絡(luò)博覽會(huì)評(píng)選金獎(jiǎng)奇石第一期活動(dòng)正式啟動(dòng)了
由中國(guó)觀賞石網(wǎng)絡(luò)博覽會(huì)組委會(huì),中國(guó)奇石展網(wǎng)主辦,河南京皓網(wǎng)絡(luò)科技有限公司、鄧州市觀賞石協(xié)會(huì)承辦的2020第三屆中國(guó)觀賞石網(wǎng)絡(luò)博覽會(huì)評(píng)選
相關(guān)內(nèi)容
- 靈御(PandaGuard) 人工智能大模型安全攻防評(píng)估平臺(tái)正式發(fā)布:人工智能北京力量護(hù)航人工智能安全穩(wěn)健發(fā)展
- 清華團(tuán)隊(duì)重要突破!Nature+1
- 清華團(tuán)隊(duì)“反轉(zhuǎn)”研究帶來意外之喜
- 山東地區(qū)史前考古研究重大成果在濟(jì)南發(fā)布
- 福建洛江馬甲杏川村的“文明基因”——以“紅”為脈 擘畫鄉(xiāng)村振興新圖景
- 福建發(fā)展高速公路股份有限公司以“三個(gè)著力”推進(jìn)學(xué)習(xí)教育走深走實(shí)
- 川酒集團(tuán)官方定制小程序煥新上線 開啟白酒個(gè)性化定制新體驗(yàn)
- 重慶市巴南區(qū)市場(chǎng)監(jiān)管局全力保障中高考飲食安全
- 歐洲央行再次下調(diào)三大關(guān)鍵利率
- 足球——世預(yù)賽:中國(guó)隊(duì)不敵印尼隊(duì)
- 2025上海國(guó)際碳中和博覽會(huì)開幕
- 關(guān)注眼健康 迎接愛眼日
- “中國(guó)游”進(jìn)階!開放的中國(guó)以更大誠(chéng)意向世界展現(xiàn)多元魅力
- 取得關(guān)鍵資質(zhì)!AES100發(fā)動(dòng)機(jī)獲頒生產(chǎn)許可證
- 葡萄牙新政府宣誓就職
- 特朗普:短時(shí)間內(nèi)促成俄烏立即停火比較困難
- 世界環(huán)境日:美麗中國(guó)我先行
- 我國(guó)成功發(fā)射衛(wèi)星互聯(lián)網(wǎng)低軌衛(wèi)星
- 加拿大商品貿(mào)易逆差創(chuàng)歷史新高
- 強(qiáng)強(qiáng)聯(lián)合 東方雨虹與順豐速運(yùn)簽署戰(zhàn)略合作協(xié)議
熱門資訊
-
靈御(PandaGuard) 人工智能大模型安全攻防評(píng)估平臺(tái)正式發(fā)布:人工智能北京力量護(hù)...
人工智能大語言模型在各個(gè)領(lǐng)域的廣...
-
 川酒集團(tuán)官方定制小程序煥新上線 開啟白酒個(gè)性化定制新體驗(yàn)
4類定制、2000多個(gè)組合,滿足12種...
川酒集團(tuán)官方定制小程序煥新上線 開啟白酒個(gè)性化定制新體驗(yàn)
4類定制、2000多個(gè)組合,滿足12種...
-
 歐洲央行再次下調(diào)三大關(guān)鍵利率
6月5日,歐洲中央銀行副行長(zhǎng)路易斯...
歐洲央行再次下調(diào)三大關(guān)鍵利率
6月5日,歐洲中央銀行副行長(zhǎng)路易斯...
-
 足球——世預(yù)賽:中國(guó)隊(duì)不敵印尼隊(duì)
6月5日,中國(guó)隊(duì)球員張玉寧(左三)在...
足球——世預(yù)賽:中國(guó)隊(duì)不敵印尼隊(duì)
6月5日,中國(guó)隊(duì)球員張玉寧(左三)在...
-
 2025上海國(guó)際碳中和博覽會(huì)開幕
6月5日,工作人員(右)在向參觀者介...
2025上海國(guó)際碳中和博覽會(huì)開幕
6月5日,工作人員(右)在向參觀者介...
-
 關(guān)注眼健康 迎接愛眼日
6月5日,在江蘇省興化市景范學(xué)校,...
關(guān)注眼健康 迎接愛眼日
6月5日,在江蘇省興化市景范學(xué)校,...
-
 “中國(guó)游”進(jìn)階!開放的中國(guó)以更大誠(chéng)意向世界展現(xiàn)多元魅力
夏日里的中國(guó),山水如畫。碧波蕩漾...
“中國(guó)游”進(jìn)階!開放的中國(guó)以更大誠(chéng)意向世界展現(xiàn)多元魅力
夏日里的中國(guó),山水如畫。碧波蕩漾...
-
 取得關(guān)鍵資質(zhì)!AES100發(fā)動(dòng)機(jī)獲頒生產(chǎn)許可證
這是6月5日在AES100發(fā)動(dòng)機(jī)研制工作...
取得關(guān)鍵資質(zhì)!AES100發(fā)動(dòng)機(jī)獲頒生產(chǎn)許可證
這是6月5日在AES100發(fā)動(dòng)機(jī)研制工作...
-
 葡萄牙新政府宣誓就職
6月5日,在葡萄牙里斯本阿茹達(dá)宮,...
葡萄牙新政府宣誓就職
6月5日,在葡萄牙里斯本阿茹達(dá)宮,...
-
 天問二號(hào)探測(cè)器在軌飛行正常 圓形柔性太陽翼展開圖片發(fā)布
截至6月6日上午,天問二號(hào)探測(cè)器已...
天問二號(hào)探測(cè)器在軌飛行正常 圓形柔性太陽翼展開圖片發(fā)布
截至6月6日上午,天問二號(hào)探測(cè)器已...
-
 2025北京智源大會(huì)開幕 智源發(fā)布“悟界”系列大模型
2025年6月6日,第七屆北京智源大會(huì)...
2025北京智源大會(huì)開幕 智源發(fā)布“悟界”系列大模型
2025年6月6日,第七屆北京智源大會(huì)...
-
 各地全力保障 暖心護(hù)航高考
6月4日,河南省沁陽市啟動(dòng)愛心助考...
各地全力保障 暖心護(hù)航高考
6月4日,河南省沁陽市啟動(dòng)愛心助考...
-
 泉州公路系統(tǒng)應(yīng)急演練 筑牢防汛安全屏障
為全面提升公路系統(tǒng)防災(zāi)減災(zāi)救災(zāi)能...
泉州公路系統(tǒng)應(yīng)急演練 筑牢防汛安全屏障
為全面提升公路系統(tǒng)防災(zāi)減災(zāi)救災(zāi)能...
-
 福建安溪:校地雙向賦能 產(chǎn)教融合打造縣域經(jīng)濟(jì)新樣本
風(fēng)從農(nóng)大來,勢(shì)從安溪起。不久前,...
福建安溪:校地雙向賦能 產(chǎn)教融合打造縣域經(jīng)濟(jì)新樣本
風(fēng)從農(nóng)大來,勢(shì)從安溪起。不久前,...
-
 警銀聯(lián)動(dòng)--工行三明將樂支行成功攔截萬元被騙資金守護(hù)百姓“錢袋子”
近日,將樂縣政府打擊治理電信網(wǎng)絡(luò)...
警銀聯(lián)動(dòng)--工行三明將樂支行成功攔截萬元被騙資金守護(hù)百姓“錢袋子”
近日,將樂縣政府打擊治理電信網(wǎng)絡(luò)...
文章排行
- 1 中國(guó)首批沙戈荒大型新能源基地外...
- 2 中國(guó)海軍第47批護(hù)航編隊(duì)紅河艦技...
- 3 第十五屆全國(guó)運(yùn)動(dòng)會(huì)獎(jiǎng)牌“同心躍...
- 4 聯(lián)合國(guó)呼吁美政府不要讓局勢(shì)進(jìn)一...
- 5 古今碰撞 科技搭橋 繪出網(wǎng)絡(luò)文...
- 6 50元一次的非法性交易,10秒不到...
- 7 5G手機(jī)限時(shí)特惠 榮耀90pro到手價(jià)3039元
- 8 寧夏首屆殘?zhí)貖W運(yùn)動(dòng)會(huì)在中衛(wèi)市開幕
- 9 蘋果iOS 16.6.1更新被黑客攻擊...
- 10 絲襪臭腳